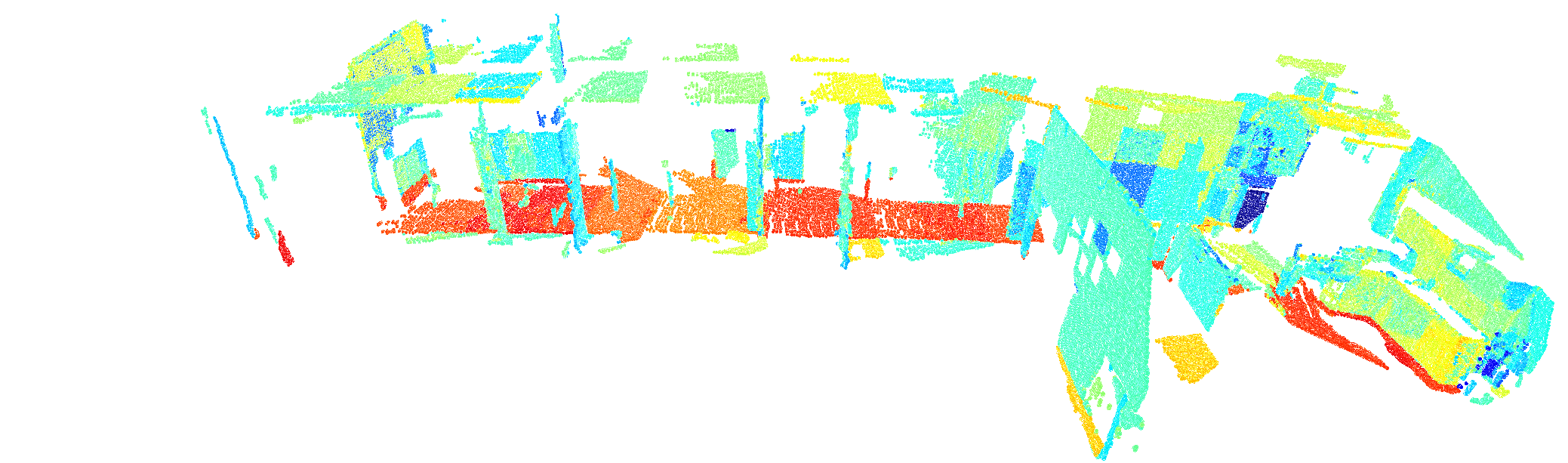Evaluation
We collect RGB-D sequences using an Orbbec Femto Bolt Time-of-Flight camera in three setups: handheld, wrist-mounted on a Franka Emika arm, and mounted on a Segway RMP Lite 220 mobile base. Color and depth images are captured at 1280x720 resolution and 30 Hz.
Query on 2D Image
We compare our method against ConceptFusion and LangSplat using two OpenCLIP variants. For evaluation, we manually annotated frames from the kitchen sequence and computed the mIoU PR AUC across multiple text queries. While LangSplat achieves higher accuracy, it fails to operate in real time due to its offline embedding pipeline. Our method offers a strong trade-off: it improves text-to-embedding alignment over ConceptFusion and achieves real-time inference at 1.53 Hz. The table below reports mIoU PR AUC scores for different text queries on the kitchen sequence. Our method with ViT-B/16 delivers the best real-time segmentation accuracy (bold). LangSplat, although included as an upper-bound reference, is not real-time capable*.
| Object | CF ViT‑H/14 |
LS* ViT‑B/16 |
Ours | |
|---|---|---|---|---|
| ViT‑H/14 | ViT‑B/16 | |||
| sugar | 0.170 | 0.070 | 0.043 | 0.075 |
| milk | 0.702 | 0.954 | 0.325 | 0.535 |
| faucet | 0.030 | 0.704 | 0.138 | 0.119 |
| towel | 0.613 | 0.875 | 0.726 | 0.709 |
| detergent | 0.159 | 0.953 | 0.291 | 0.288 |
| chair | 0.895 | 0.570 | 0.375 | 0.346 |
| coffee machine | 0.403 | 0.972 | 0.685 | 0.779 |
| sink | 0.495 | 0.699 | 0.529 | 0.569 |
| socket | 0.354 | 0.763 | 0.396 | 0.362 |
| sponge | 0.404 | 0.677 | 0.235 | 0.281 |
| paper towel | 0.365 | 0.516 | 0.459 | 0.559 |
| table top | 0.261 | 0.537 | 0.399 | 0.494 |
| average | 0.404 | 0.691* | 0.383 | 0.426 |
Text-Based 3D Querying
By combining camera pose estimation, masked local embedding extraction, and their integration into a 3D map,
our method produces a unified color and embedding representation in real time.
We qualitatively compare query responses on the kitchen sequence against ConceptFusion and LangSplat.
Unlike these baselines, which operate offline, our system processes streaming data and selectively skips
frames to maintain real-time performance.
Our multivalued hash map yields fewer visual artifacts than ConceptFusion's point cloud and outperforms
LangSplat in unobserved regions, while also providing metric-accurate geometry essential for robotic
applications.
3D environment reconstruction of the kitchen sequence with similarity heatmaps for text queries
(blue: low, red: high).
The queries coffee machine, milk, sink, and socket are marked using red and
black bounding boxes, respectively.
Thanks to the use of masked local embeddings, our method produces sharper query responses compared to
ConceptFusion and exhibits fewer outliers than LangSplat.
Additionally, our dense color model (first row) contains significantly fewer visual artifacts.
 coffee machine
coffee machine


 milk
milk


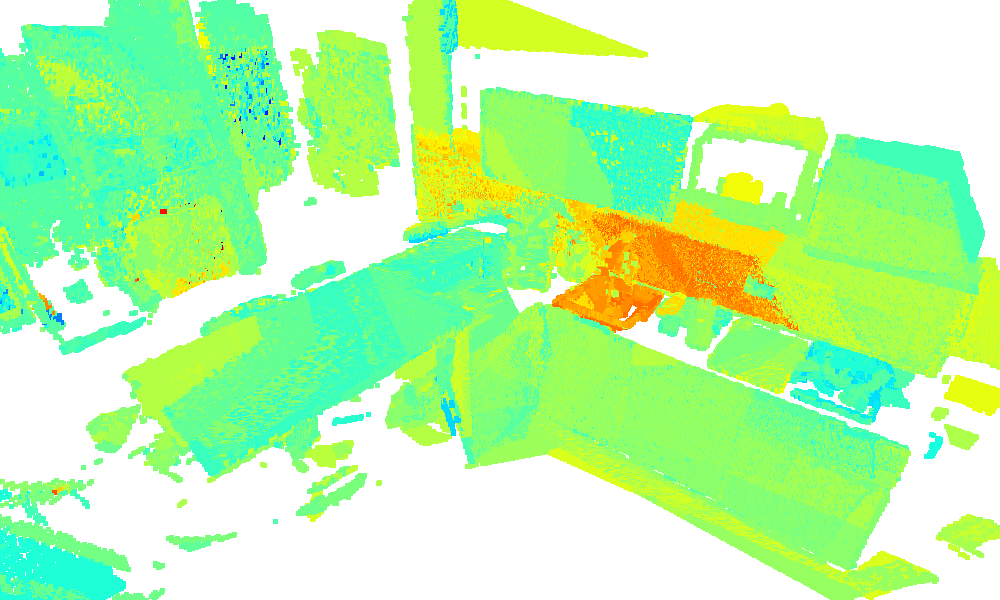 sink
sink


 socket
socket


 sponge
sponge


 table top
table top


 towel
towel


 paper towel
paper towel

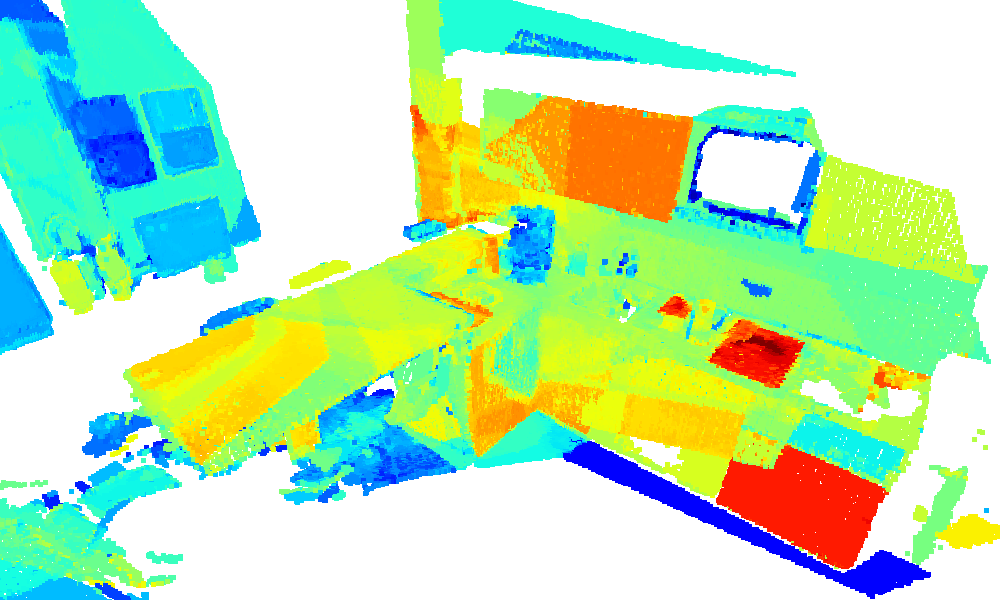
 chair
chair


 detergent
detergent

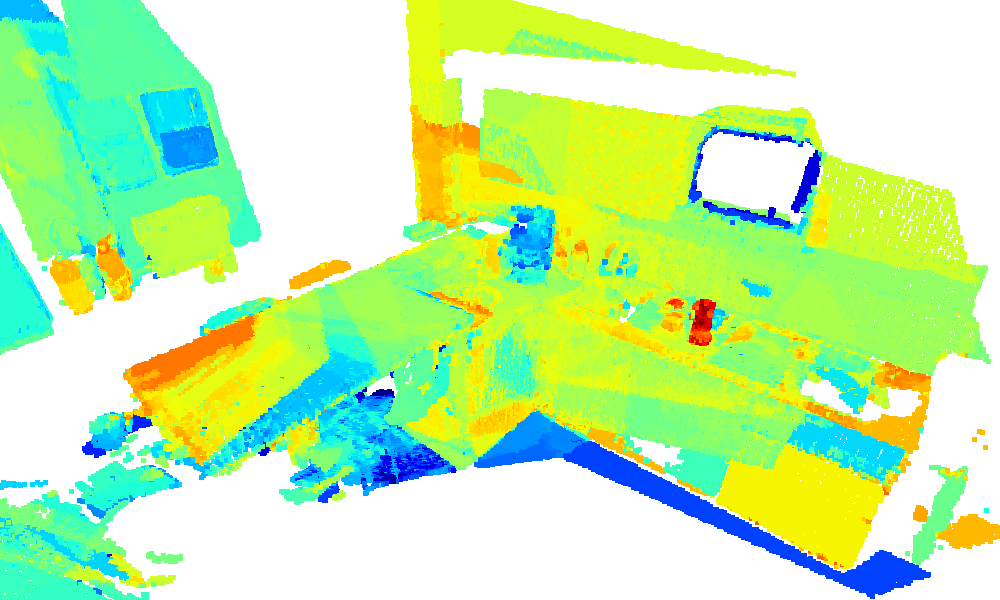
 faucet
faucet


 sugar
sugar

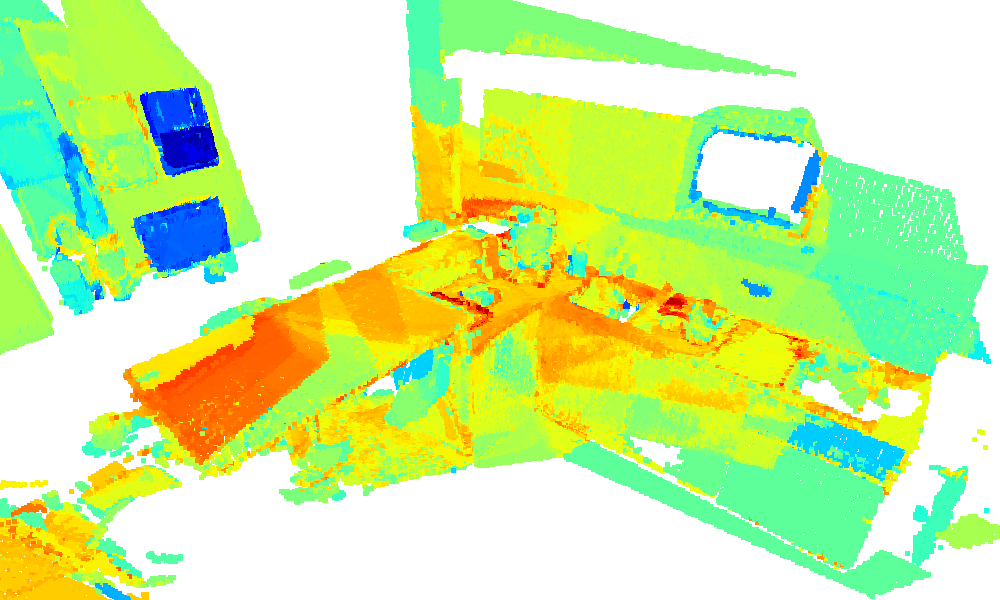
We showcase qualitative reconstructions and similarity heatmaps from the kitchen, workshop, and table sequences, demonstrating how query specificity affects localization. In the kitchen, a general query like coffee highlights both the coffee machine and the milk carton, capturing broader contextual relevance. In contrast, querying for milk results in a focused response limited to the milk carton. Similarly, in the workshop, a precise query for the Bosch drill produces a sharper activation than the more generic drill query. These examples highlight the open-set nature of our method, enabling flexible interaction across diverse environments and semantic levels.
 RGB Image
RGB Image
 Query: coffee
Query: coffee
 Query: milk
Query: milk
 RGB Image
RGB Image
 Query: toolbox
Query: toolbox
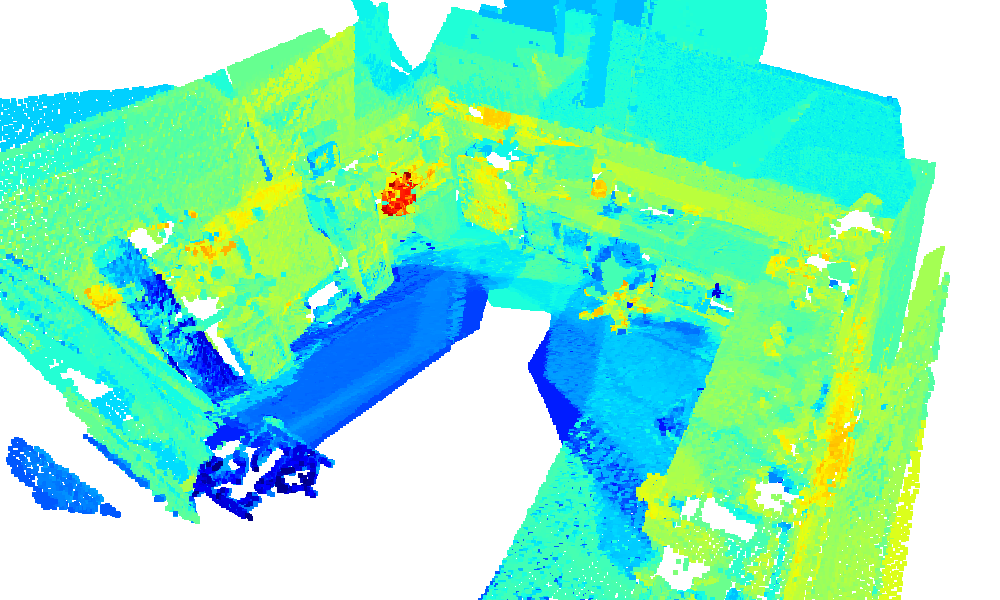 Query: lathe
Query: lathe
 RGB Image
RGB Image
 Query: drill
Query: drill
 Query: Bosch drill
Query: Bosch drill
 RGB Image
RGB Image
 Query: power supply
Query: power supply
 Query: drawer
Query: drawer
 RGB Image
RGB Image
 Query: plant
Query: plant
 Query: table
Query: table